
属实没念念到,卡着全天下迁移芯片脖子的Arm,瞬息发布了自研CPU!
智东西3月24日旧金山现场报谈,刚刚,3500亿颗芯片背后的半导体IP巨头Arm,推出首款由Arm自主想象的数据中心CPU——Arm AGI CPU。

▲Arm CEO Rene Haas展示AGI CPU芯片
这是Arm发展35年来,初度推出对外售售的自研芯片,亦然Arm全新数据中心芯片家具线的首款家具,记号着Arm肃穆艰难数据中心芯片界限,将其高能效架构范围化引入AI基础设施。
Arm AGI CPU专为AI智能体基础设施打造,汲取台积电3nm制程工艺、双Chiplet想象,单颗CPU集成多136个Arm Neoverse V3高性能中枢,配备2MB L2缓存,支握3.7GHz主频,提供每中枢6GB/s内存带宽,内存时延低于100ns,汲取96通谈PCIe Gen 6接口,支握CXL 3契约,TDP达300W。

Arm将其称作“寰球最高能效的智能体CPU”,围绕性能、范围、能效三个原则来想象。

英伟达首创东谈主兼CEO黄仁勋的巨脸出咫尺大屏幕上,祝颂Arm发布第一款数据中心芯片。

Arm AGI CPU的单核、系统级芯片、刀片式干事器及机架各层级均已毕行业最初的性能发达。
通过更多可用线程与更高单线程处理才调相相互通,该芯片可已毕单机架性能达到x86平台的2倍以上,每1GW的AI数据中默算力本钱支拨省俭高达100亿好意思元。

它支握高密度1U干事器机箱的风冷部署有商量,单机架可支握多达8160个筹画中枢;也支握液冷系统,单机架可已毕超越45000个中枢的部署范围。

Arm CEO Rene Haas分享说,按其估算,自东谈主类降生以来,纯粹共有1170亿东谈主生存在这个星球上。而Arm芯片累计出货量已超越3500亿颗,足足是有史以来东谈主类总和的3倍,是悉数非Arm架构CPU累计出货量总和的7倍,平均每个寰球家庭领有160颗Arm芯片。
咫尺,Arm的中枢业务包括三大块:IP授权、CSS(筹画子系统)有商量,以及自主想象的芯片家具。

Arm AGI CPU现已敞开订购,已交到客户手中,正在由客户评估,商量在年底前已毕量产。

Arm与永擎电子、联念念、广达电脑、Supermicro等头部OEM厂商及ODM厂商伸开互助,早期系统现已推出,永擎电子、联念念及Supermicro已敞开商用系统订购,更平常的商用部署瞻望将于本年下半年落地。

▲联念念HR650A V3 2U机架干事器,配备两颗Arm AGI CPU
Arm还显露了后续家具盘算,AGI CPU与Arm Neoverse CSS家具门道图将并行鞭策,商量2027年发布Arm AGI CPU 2和CSS V4,异日发布Arm AGI CPU 3和CSS V5,确保悉数Arm数据中心客户在平台架构与软件兼容性方面已毕协同发展。

在会后媒体问答法子,Rene Haas谈谈,研发AGI CPU仅仅Arm交易模式的当然延长,商场需求严重未被得志,中国可能曲直常好的商场。
另据Arm云AI职业部实行副总裁Mohamed Awad分享,Arm也在厚爱磋议NVLink等互连技巧,已告示将在异日版块的CSS中支握NVLink。
01.
汲取简化架构,莫得多线程,
解脱x86 CPU的极度开销与复杂性
Rene Haas谈谈,智能体的爆炸式增长催生更大的CPU需求。智能体本色上是一个职责流,大齐职责触及调养,这恰是CPU所擅长的职责,是加快器作念不了的。
打个比喻,加快器负责生成token,就像推一辆翻斗车,需要有东谈主去搬运土,CPU便是搬运这些土的开导。
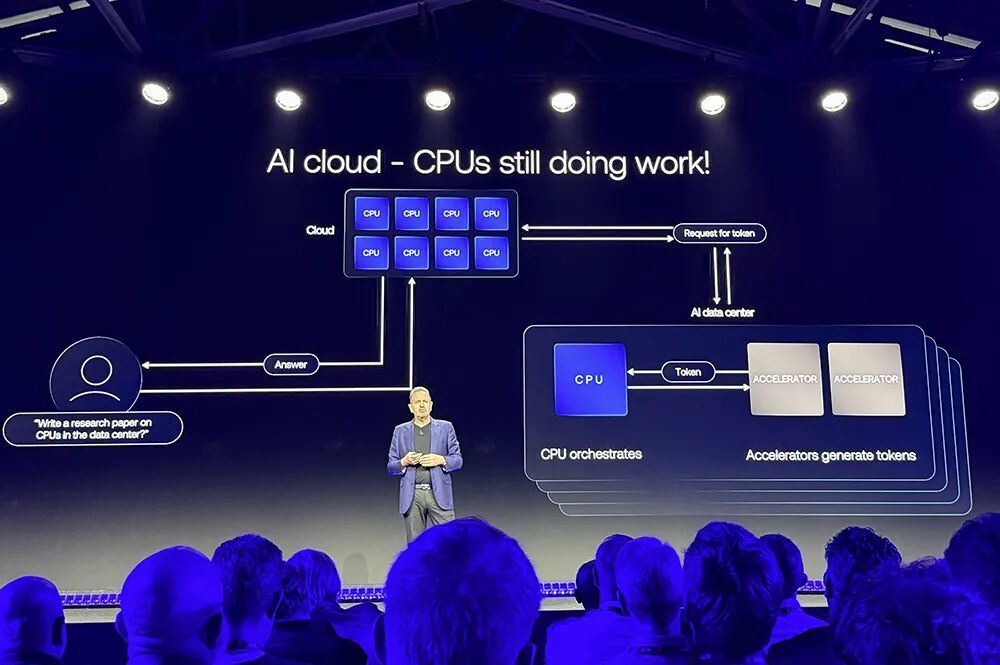
把柄Arm的估算,数据中心对每GW功耗提供的CPU算力需求将增长至现时的4倍以上,在研究功耗范围内,畴昔需要3000万CPU中枢,咫尺需要隘入约4倍的1.2亿个CPU中枢。
功耗是难得的,所需本钱亦然难得的。试图将如斯多的极度CPU塞进一个一经被加快器和实行中枢职责的CPU塞得满满当当的数据中心,是沿路难题。

对此,Arm打造了其首款对外售售的自研芯片——Arm AGI CPU。
为什么要作念这件事?Rene Haas谈谈,跟着智能体AI走向主流,悉数扶助其运转的职责齐依赖CPU,这颗CPU必须天生就具备在电板供电下运行的基因。
x86架构拖累委果行开销和对留传功能的支握拖累,选用了聚焦于模块化、支握大齐不同商场和小众用例。而Arm专注于普及能效、裁减延迟。

Arm AGI CPU从零运转想象,围绕三个原则:性能、范围、能效。

(1)性能
高IPC(每周期提醒数)一直是Arm的毅力。传统CPU偶而会试图通过提高主频、参预Boost模式来在这一维度上竞争,但提高主频,功耗也随之上升,这些Boost模式无法永久握续,也无法在整颗芯片上握续。而AGI CPU能提供全时辰、可握续的满血性能。
(2)范围
Arm在中枢数目上已毕线性推广,内存和IO子系统历程特意想象,与中枢高度匹配。
一些传统架构汲取多线程。多线程的实质是向兼并个中枢丢两个任务,但IO和带宽并不会因此翻倍,仅仅把瓶颈滚动到了别处,况且CPU还必须承担责罚这种往来切换的拖累,导致性能下落,最终导致进度饥饿。
Arm反复不雅察到,数据中心运营商不得不逾额确立数据中心30%以致更多,来冒失这种非线性推广的问题。
Arm以无需这么作念为傲。

▲AGI CPU与x86 CPU运行兼并任务的发达对比
(3)能效
Arm对能效有着近乎过火的专注。AGI CPU是专为操办场景打造的,莫得任何留传架构的包袱,不滥用任何一个周期,不存在搁浅的算力,不滥用任何一瓦的功耗。
在实测中,AGI CPU可提供握续性能,莫得因超出功耗预算而导致的性能降频,莫得内存或IO争用。
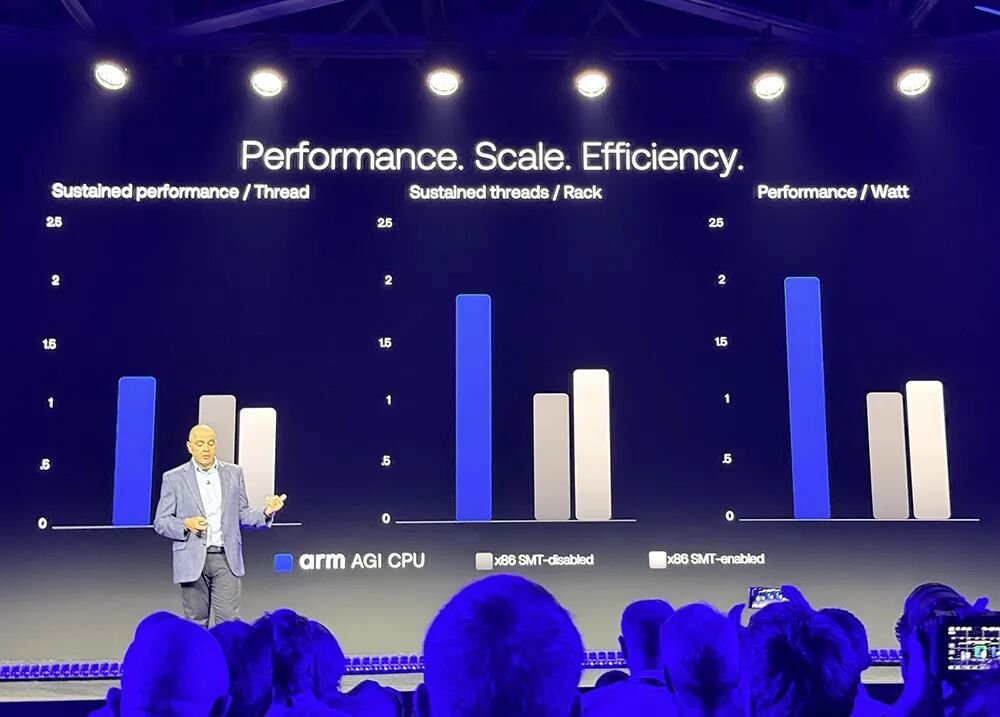
上图中,左边的AGI CPU和中间的x86 CPU柱形均在SMT(同步多线程)禁用的情况下测得,仅对比了单线程中枢发达。
一个常见说法是,多线程能改善性能,带来更好的可推广性。但如若开启多线程,闭幕如图中第三个柱形所示,性能下落、实践中每机架大齐线程闲置、能效略有普及但不及以改变举座的算法弃取。
Mohamed Awad确认注解说,如若对内存带宽的需求很低,SMT是合理的,因为不错分享带宽,当一个线程在恭候时,可将CPU资源让给另一个线程。
但在智能体AI场景中,有大齐线程需要同期扶助,有不菲的加快器和不菲的基础设施在恭候,最不但愿发生的事情便是分割I/O带宽或内存带宽,而是但愿将那些I/O和内存带宽精准地专用给对应的进度。
“咱们以为,这个最优值约为每秒4~6GB的带宽分派给每个中枢,这恰是咱们的想象操办。在这类场景下,空幻现SMT是更合适的选用,因此咱们咫尺莫得汲取SMT的商量。”他谈谈。
02.
详解AGI CPU规格:
3nm、136核、3.7GHz主频
从运行频率到内存及I/O架构,Arm AGI CPU每一处想象齐历程特意优化,在高密度机架部署场景下,支握大范围并行、高性能的智能体AI职责负载。
AGI CPU汲取台积电3nm制程工艺,基于治安Arm Neoverse V3筹画子系统,单颗CPU集成多136个Arm Neoverse V3高性能中枢,配备2MB L2缓存,支握高达3.7GHz的主频。

该芯片提供每中枢6GB/s内存带宽。最初的内存带宽使每个机架能支握更多高效实行的线程。比较之下,x86 CPU在握续高负载下会因中枢争抢资源而导致性能下落。

Arm将悉数这个词系统想象为低延迟架构,使内存侦察延迟低于100纳秒。
为此,AGI CPU汲取了双Chiplet想象,每个Chiplet将悉数内存和IO获胜集成其上,无需担忧复杂的NUMA域和跨硅片的屡次跳转。
在互联方面,Arm AGI CPU汲取96通谈PCIe Gen 6接口,支握CXL 3契约,可络续淘气加快器,同期支握内存推广等功能。

其TDP(热想象功耗)为300W,每线程独处中枢,可在握续负载下提供细则性性能,幸免降频与线程闲置。
03.
支握风冷和液冷,
单机架性能达x86系统的2倍以上
为加快家具汲取,Arm推出Arm AGI CPU1OU双节点参考干事器。该干事器汲取适当OCP(敞开筹画情势,Open Compute Project)的DC-MHS治安规格想象。

Arm的参考干事器汲取1OU双节点想象,每台刀片干事器中集成2颗CPU芯片,并配备独处内存与I/O,共计272个中枢。

AGI CPU支握高密度1U干事器机箱的风冷部署有商量。下图是一个治安OCP风冷机架。这些刀片干事器可在治安风冷36kW机架中满配部署,30台双节点1OU刀片干事器可提供共计8160个中枢。

在该确立下,Arm AGI CPU可已毕单机架性能达到最新x86系统的2倍以上。

此外,Arm与Supermicro互助推出200kW液冷想象有商量,可容纳336颗Arm AGI CPU,提供超越45000个中枢。
Arm商量向OCP社区孝顺该参考干事器想象有商量及配套固件,并进一步提供包括系统架构标准、调试框架及适用于悉数Arm架构系统的会诊与考证器具等资源。
这些孝顺将惠及悉数这个词生态系统,对悉数基于Arm的平台均有裨益。
更多细节将在行将举办的OCP EMEA峰会上公布。
04.
与Meta贯串开发,
还有多家首发互助伙伴
Meta、OpenAI高管均来到Arm Everywhere大会现场并登台分享。
Meta动作Arm AGI CPU的早期互助伙伴与客户,参与该CPU的贯串开发,旨在为Meta全系垄断优化GW级范围基础设施,并与Meta自研MTIA推理加快器协同运行,从而在大范围AI系统中已毕更高效的编排与调养。

“这场结亲,我个东谈主以为是双赢的,相配令东谈主上升,看到从单纯的IP授权提供商,走向确实参与构建分娩级、分娩就绪家具的行列,”Meta基础设施负责东谈主Santosh Janardhan谈谈,“我以为最甘好意思的事情需要一些时辰,而咱们咫尺就要到了。”
他说Meta和Arm谈互助,核情绪由是念念在每瓦内放入更多的中枢,但不念念在性能上有任何和洽。
咫尺每天有约35亿东谈主使用Meta的家具。每一次交互、每一篇帖子、每一个信息流、每一通电话,齐设立在Meta后端构建的基础设施之上,即定制数据中心、定制硬件和定制芯片。
纯粹两年半前,Meta先作念了商场调研,望望是否有哪款CPU能得志规格条件,闭幕要么得志了性能、功耗不得志,要么得志了功耗、性能不达标。
而Arm提供的可推广性,让Meta省略注入更多算力,作念到了优化每瓦性能、每千兆瓦性能、优化Meta全平台性能。
两边喜悦将围绕Arm AGI CPU的多代芯片家具伸开永久深度互助。
其他首发互助伙伴包括Cerebras、Cloudflare、F5、OpenAI、Positron、Rebellions、SAP及SK电讯。
这些客户将在智能体CPU中枢垄断场景中部署Arm AGI CPU,障翳加快器责罚、截至平面处理、云与企业级API、任务与垄断托管等界限。
在大会展区,SK电信旗下Rebellions展示了使用Arm AGI CPU动作头节点,在兼并台干事器中有一批加快器的实例。

Arm展示了雄壮的“一又友圈”。超大范围筹画干事商、云筹画、芯片、内存、收罗、软件、系统想象与制造等界限的50余家行业龙头企业,均对Arm筹画平台向芯片界限拓展示意支握。

英伟达、谷歌、微软、亚马逊云科技、博通、Marvell、好意思光、微软、三星、SK海力士、台积电等企业的高管一通猛夸,以为Arm AGI CPU是悉数这个词生态系统发展的病笃里程碑,将带来新一代定制化筹画才调,进一步开释Arm生态系统的后劲,让更多客户省略通俗地得回Arm的筹画才调,为悉数基于Arm构建智能异日的互助伙伴创造新的要紧机遇。
“咱们很自重能与Arm共同构建这个敞开、可推广、高能效的AI异日。加快筹画并莫得让CPU变得不足轻重,它让CPU成为不能或缺的互助伙伴。Arm架构一经成为咱们悉数平台的基础。”黄仁勋说,“Arm的适合性和可定制性,确实使咱们省略将Arm整合至悉数平台之中。”
05.
结语:云表AI业务有望成Arm最大扶助,
异日剑指1万亿好意思元商场
“寰球莫得任何一家公司的生态系统,能像咱们这么从角落端到云表清爽干事。”Rene Haas说。
他预测,云表AI业务可能在几年内成为Arm最大的业务。
如今更难仆数的公司在云表运行其软件于Arm之上,依托已向寰球数据中心委派的超越12.5亿个Arm Neoverse中枢。这一增长仍在加快。

三十多年来,产业界基于Arm筹画平台握续转换,在数千亿台开导上已毕了可推广、高能效的筹画才调。悉数这个词生态系统正寻求大范围部署Arm技巧的有商量。

“今天记号着Arm筹画平台迈入全新发展阶段,也成为公司发展的病笃里程碑。”Rene Haas谈谈,AI从根柢上重塑了筹画的构建与部署,智能体筹画正加快这一变革,跟着Arm AGI CPU芯片推出,Arm将助力智能体AI基础设施已毕寰球范围化部署。
在注目智能体AI发展、CPU需求增长、高能效CPU为数据中心带来的价值后,Arm预判这在异日将代表约1000亿好意思元的TAM。

“将咱们在悉数商场上积蓄的恶果,从角落到云表,从毫瓦到千兆瓦,咱们有契机在一个1万亿好意思元量级的商场中大展技艺。”Rene Haas说。
